.svg)

Models
Develop, train, track and register machine learning models in a unified environment with native MLflow integration. Creates a traceable, reproducible record of data/model provenance.


Key capabilities
Track model development with native MLflow
Native integration with MLflow lets you track the development of your models with no additional setup. Click to track model development from any Capsule.

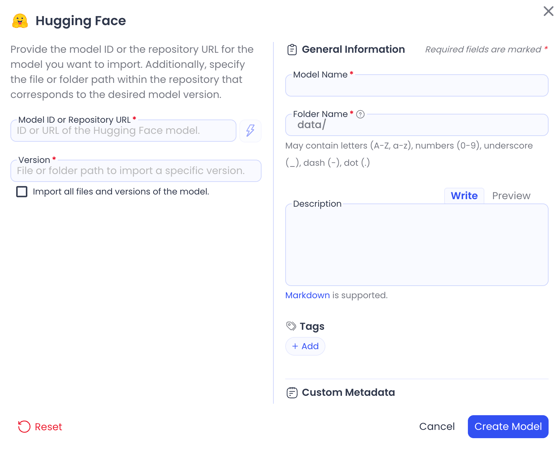
Import Hugging Face models with built-in integration
Native Hugging Face integration lets you import HF models and their associated metadata into a Code Ocean asset. Use them in Capsules or Pipelines and benefit from automated provenance and lineage.
Handle changing GPU needs at every step
Define any CPU, GPU and RAM requirements for every step of development. Scale cloud up and down as needed with flexible and reliable Dockerized environments.

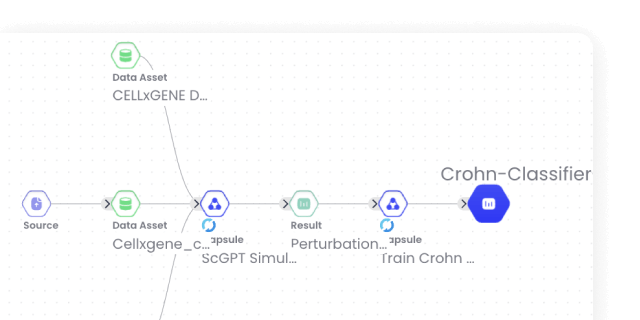
Get full data lineage for every model
Need to find out what dataset a registered model was trained on, and what code you ran when you were developing it? Now you can use our Lineage Graph feature to find out in seconds.

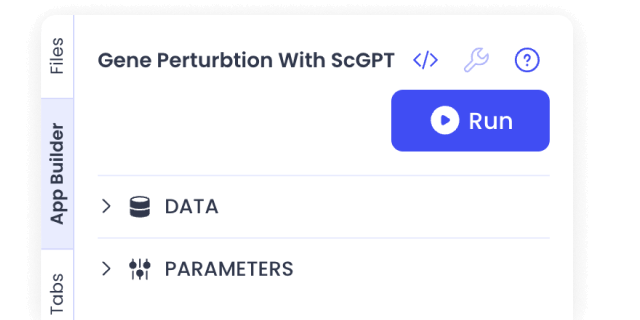
Create no-code apps for inference with non-coders
Validate with confidence before pushing to production by releasing no-code inference versions of your model with a single click. Non-coding users can run it in the cloud without help, and hotswap their data.

How Models work with the rest of the Code Ocean platform

Frequently asked questions
 Models
Models
Is this MLflow integration secure?
Yes. We’ve natively integrated MLflow into the Code Ocean platform, so it inherits the existing security features of the platform: Industry-standard permissions and access management with identity provision and single sign-on (IDP and SSO).
What is “pre-production” and how is Code Ocean uniquely designed to address it?
Pre‑production is the bridge between dev and prod where domain experts test a “finished” model on real data. Code Ocean solves it with Capsules, by packaging the model, environment, and a simple UI into a shareable asset so domain experts can upload data, click Run, and evaluate, all with a few clicks.
Built for Computational Science
-
Data analysis

Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
-
Data management

Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
-
Bioinformatics pipelines

Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
-
ML models
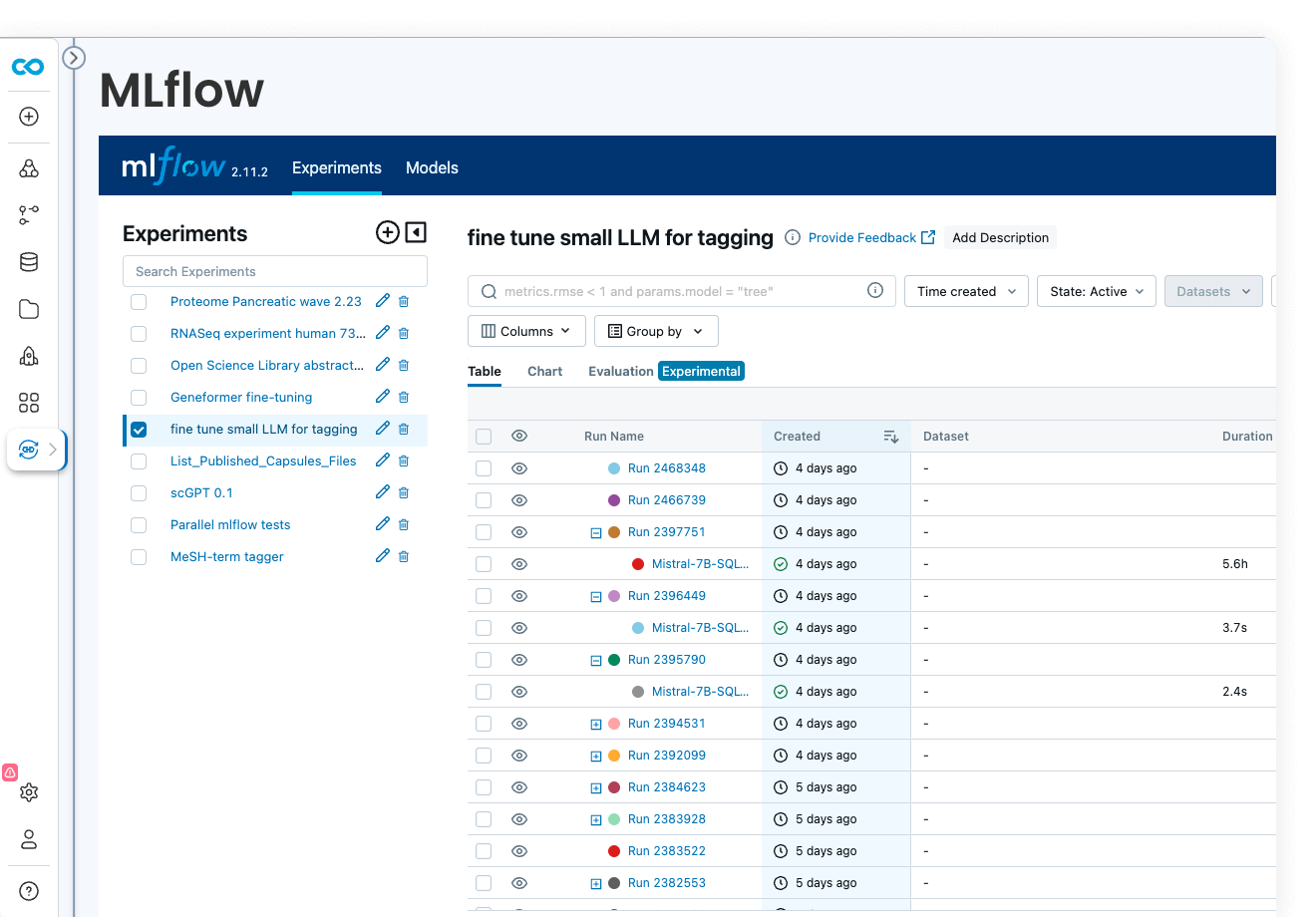

ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
-
Multiomics


Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
-
Imaging
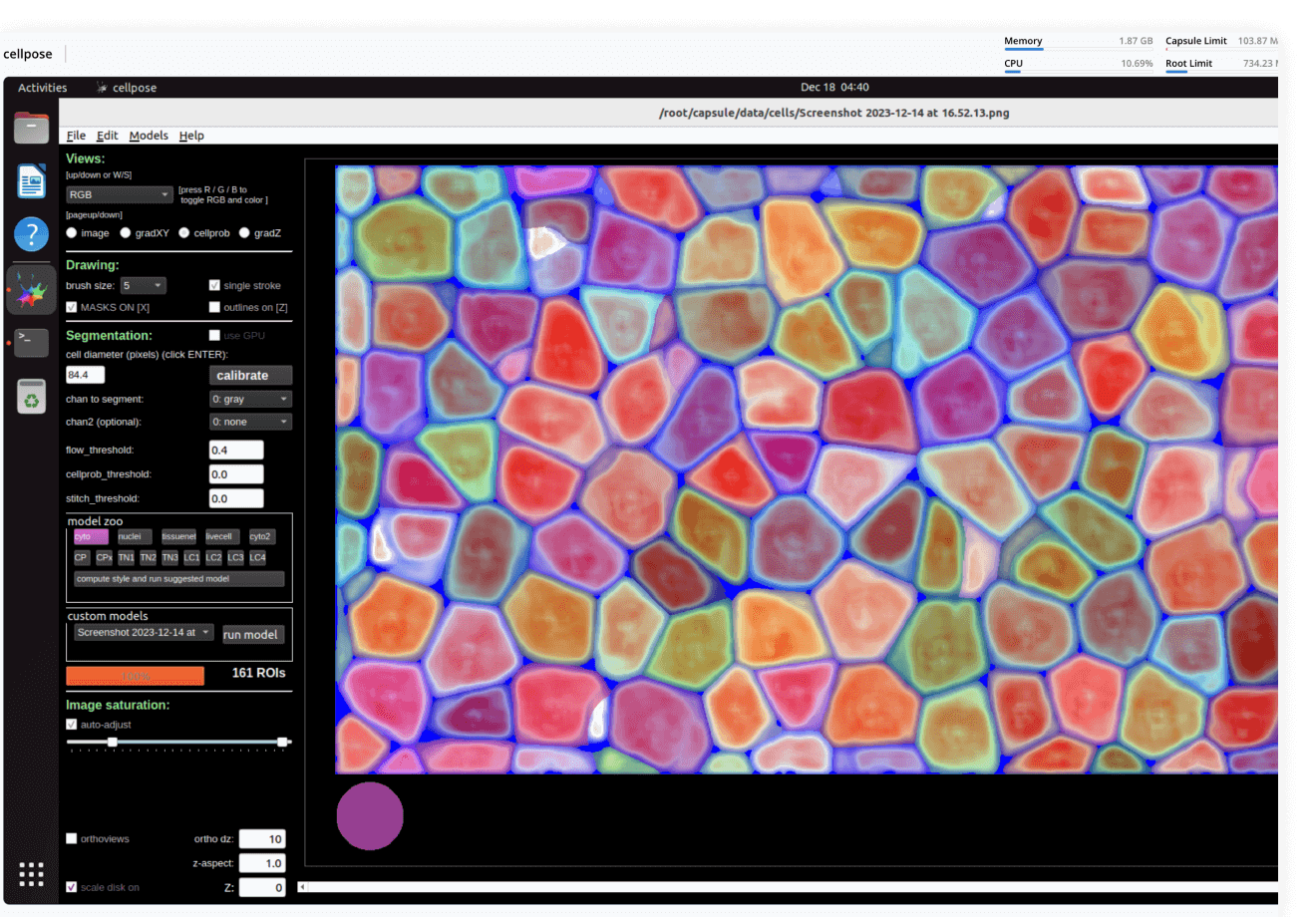

Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
-
Cloud management


Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
-
Data/model provenance

Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
Data analysis
Use ready-made template Compute Capsules to analyze your data, develop your data analysis workflow in your preferred language and IDE using any open-source software, and take advantage of built-in containerization to guarantee reproducibility.
Data management
Manage your organization's data and control who has access to it. Built specifically to meet all FAIR principles, data management in Code Ocean uses custom metadata and controlled vocabularies to ensure consistency and improve searchability.
Bioinformatics pipelines
Build, configure and monitor bioinformatics pipelines from scratch using a visual builder for easy set-up. Or, import from nf-core in one click for instant access to a curated set of best practice analysis pipelines. Runs on AWS Batch out-of-the-box, so your pipelines scale automatically. No setup needed.
ML model development
Code Ocean is uniquely suited for Artificial Intelligence, Machine Learning, Deep Learning, and Generative AI. Install GPU-ready environments and provision GPU resources in a few clicks. Integration with MLFlow allows you to develop models, track parameters, manage models from development to production, while enjoying out-of-the-box reproducibility and lineage.
Multiomics
Analyze and work with large multimodal datasets efficiently using scalable compute and storage resources, cached packages for R and Python, preloaded multiomics analysis software that works out of the box and full lineage and reproducibility.
Imaging
Process images using a variety of tools: from dedicated desktop applications to custom-written deep learning pipelines, from a few individual files to petabyte-sized datasets. No DevOps required, always with lineage.
Cloud management
Code Ocean makes it easy to manage data and provision compute: CPUs, GPUs, and RAM. Assign flex machines and dedicated machines to manage what is available to your users. Spot instances, idleness detection, and automated shutdown help reduce cloud costs.
Data/model provenance
Keep track of all data and results with automated result provenance and lineage graph generation. Assess reproducibility with a visual representation of every Capsule, Pipeline, and Data asset involved in a computation.
.png?length=720&name=September%20Webinar%20-%20On%20Demand%20(1).png)
